RAG from scratch series - part 2
Welcome to the second part of building the RAG (Retrieval Augmented Generation) system from scratch. In case you've missed it, please have a look at the first part of the blog. In this blog post, we are going to put the pieces together and create our final product.
First part recap
Before we jump into the topic, let's quickly recap what we did in the previous blog post. The first part was solely focused on data preparation. Remember, we are building a RAG system for a company called Gitlab and we've used the Gitlab Handbook which is a collection of official company documents.
Our first step was to split these documents into smaller parts via a process called chunking. In the second step, we've taken these chunks and turned them into embeddings. Then we stored the chunks along with their embeddings into JSON files so that they can be further consumed by our system.
Now that we have our data ready, it's time to put it into use. We will also solve the mystery of why we did chunking in the first place, but the most important part is that we are going to build the three famous components:
- Retrieval
- Augmentation
- Generation
All the code is located in my Github repository
Retrieval
The way users are going to interact with our system is by asking questions. To give you an idea what this looks like, here are some example questions:
- What is the average retention rate of employees?
- What are some of the company values at Gitlab?
- How does the interview process look like?
Our records consist of roughly 3100 chunks and the goal of the retrieval phase is to narrow this down to just 3 chunks. In other words, we are going to take the user question and somehow find 3 chunks that are most relevant to that question.
The retrieval phase can return more (or less) than 3 chunks, this can be 5 or 10, it depends on the size of your chunks, documents, which LLM you use, etc. Building a RAG involves a lot of experimentation, tweak the system until you find the best results.
The integral part of the retrieval phase is embeddings. Recall that we've converted our chunks to embeddings, however, the questions from our users come in the form of text. We need to level the playing field by converting the question into an embedding.
Inside the retrieval script we take the user question and convert it into an embedding with the same OpenAI API that was used before. Then we load all our previously stored chunks and their embeddings. Now that we've turned everything into embeddings we just need to search for the relevant chunks. 🧐
def retrieval(user_question: str) -> list[dict]:
response = openai_api_client.embeddings.create(input=user_question, model=os.environ.get('EMBEDDING_MODEL'))
embedding_from_user_question = response.data[0].embedding
stored_chunk_embeddings = load_chunks_with_embeddings()
all_chunks_with_similarity_score = perform_vector_similarity(embedding_from_user_question,
stored_chunk_embeddings)
three_most_relevant_chunk = all_chunks_with_similarity_score[:TOP_NUMBER_OF_CHUNKS_TO_RETRIEVE]
return three_most_relevant_chunkEmbeddings are numerical representations of our data within a multidimensional space. Here is a visual representation of it. We've also noted that embeddings capture meaning and relationships within our words/sentences and that similar sentences will be located closer to each other within this multidimensional space.
Let's look at a simplified example. All dots in this image are embeddings. The user question is the orange dot. Blue dots are our chunks. We are going to calculate how far is the orange dot from every other blue dot. Then we are going to pick the 3 blue dots that are the closest to the orange dot.
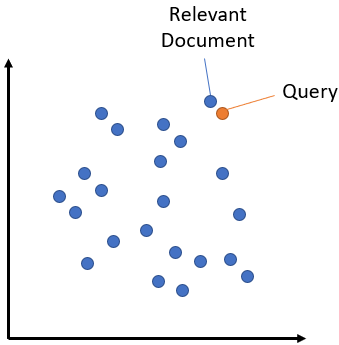
This distance calculation is called similarity search and with the 3 chunks extracted from our records, the retrieval phase is complete!
Augmentation
The goal of any RAG system is to provide new information or data to a large language model. This is the data that the model has never seen before or wasn't trained on. Let me show you an example.
I went ahead and asked ChatGPT - What is the average retention of employees at Gitlab? You can see that ChatGPT didn't provide an answer and even told us a reason for that - without access to their internal data, I can't provide the answer.
The good news for you ChatGPT is that we have the data! 😂This is where augmentation steps in, we are going to help our LLM answer this question by providing the necessary information. To be very precise, we are going to take those 3 chunks from the previous step and inject them into the prompt!
Let's have a look at the augmentation script. We have a system prompt where the model is instructed on what to do with the documents.
DOCUMENTS_DELIMITER = '+++++'
SYSTEM_PROMPT = f'''You are a helpful assistant who works at a company called Gitlab.
Your job is to answer questions based on the company documents.
Use the provided documents delimited by {DOCUMENTS_DELIMITER} to answer questions. If the answer cannot be found in the documents, write
"Sorry, I could not find an answer to your question. Please try a different one."
'''
def augmentation(user_question: str,
relevant_chunks: list[dict]) -> list[ChatCompletionMessageParam]:
system_message = ChatCompletionSystemMessageParam(content=SYSTEM_PROMPT, role='system')
user_prompt = ''
for chunk in relevant_chunks:
user_prompt += f"Document title: {chunk['title']}\n"
user_prompt += f"Document description: {chunk['description']}\n\n"
user_prompt += f"{chunk['chunk_text']}\n"
user_prompt += f"{DOCUMENTS_DELIMITER}\n"
user_prompt += f"\n\n Question: {user_question}"
user_message = ChatCompletionUserMessageParam(content=user_prompt, role='user')
print('***** Prompt to be sent off to LLM *****')
print(SYSTEM_PROMPT)
print(user_prompt)
return [system_message, user_message]We then go through all the chunks and append them to the system prompt, along with the user question at the very end. Here is an example of how the final prompt looks like.
It's important to instruct the model on what to do when it can't find an answer in the provided documents. This prevents hallucinations and overall creates a better system.
The additional information we supplement to the LLM is commonly referred to as context. Each LLM has a limitation on its context window size. In other words, there is a limit on how much text you can send to an LLM. This is the reason why we do chunking and why we extract only 3 chunks. It's because we can't fit the whole document inside a context window. Context window size varies between models such GPT-4 or GPT-3. The bigger the context window, the pricier it gets.
As the LLM models grow more powerful, we might not need chunking in the future. The latest model from Google called Gemini boasts 1 million tokens context window. This is more than enough to fit whole documents.
With our prompt ready, the time has come to get our answer.
Generation
Our generation script is trivial. Since we created the prompt, we just need to send it to the LLM with the help of OpenAI Completions API.
def generation(prompt_messages: list[ChatCompletionMessageParam]) -> str:
response = openai_api_client.chat.completions.create(
messages=prompt_messages,
model=os.environ.get('CHAT_COMPLETION_MODEL'),
temperature=0,
)
return response.choices[0].message.contentFor this whole post, we just need to run a single script called rag which combines our previous three steps. Call the script by passing the user question poetry run python3 rag.py "What is the average retention of employees at Gitlab?".
Lo and behold GenAI magic!🧙♂️

Try asking "What is the circumference of Earth?" to see how our model behaves when it can't find an answer in the provided documents.
Wrap up
There we go, our RAG system is complete. Hopefully, the term now sounds less daunting after we've disassembled it and built each piece individually. Of course, our system is nowhere near production with plenty of improvements that can be made, but our goal was to learn the concepts and I hope I covered that. The good part is that we have a baseline system to improve upon with some topics that will be covered in upcoming blogs.
In case you like my content and would like to see more of it, you can follow me on Linkedin, Mastodon, X